1. Guía de Arquitectura de GBDS 4¶
1.1. Resumen¶
GBDS es el componente ABIS de Griaule Biometric Suite. GBDS 4 está implementado sobre el marco Apache Hadoop 3 y utiliza muchas de sus herramientas y componentes (como Kafka, Zookeeper, Ambari, HBase y HDFS) para implementar un ABIS escalable, distribuido y tolerante a fallos (Sistema de Identificación Biométrica Automatizado).
GBDS es responsable de:
- Almacenamiento: Persistir registros biométricos, solicitudes y respuestas de clientes, resultados de operaciones y registros en una base de datos distribuida, escalable y tolerante a fallos.
- Extracción: Procesar datos biométricos crudos para calcular plantillas que se utilizarán para la identificación biométrica.
- Identificación: Realizar la identificación biométrica de manera eficiente distribuyendo la carga en una colección de hosts (nodos).
- Procesamiento de solicitudes: GBDS recibe solicitudes de clientes, administra su ejecución dentro de los nodos del sistema y notifica de manera asíncrona a los clientes cuando las respuestas están disponibles. Las solicitudes se realizan a través de una API HTTP/HTTPS. GBDS implementa un punto final de alta disponibilidad y alto rendimiento para las solicitudes de los clientes.
Este documento describe la arquitectura de GBDS 4.
1.2. Componentes de Hadoop¶
Apache Hadoop 3 es una colección de herramientas y componentes de código abierto para el desarrollo de sistemas distribuidos. Hadoop está basado en Java, una tecnología presente en más de 13 mil millones de dispositivos. El desarrollo de Hadoop comenzó en 2006 y pronto se convirtió en el estándar de facto para sistemas distribuidos tolerantes a fallos y de alta disponibilidad. A partir de 2013, Hadoop ya estaba presente en más de la mitad de las empresas Fortune 50.
GBDS utiliza varias herramientas y componentes del ecosistema de Apache Hadoop 3:
- HDFS es un sistema de archivos distribuido, escalable y portátil. HDFS proporciona distribución transparente de datos entre nodos de almacenamiento y almacenamiento eficiente de archivos grandes y colecciones grandes de archivos.
- HBase es una base de datos no relacional distribuida y está construida sobre el sistema de archivos HDFS.
- Zookeeper es una tienda de valores clave distribuida y se utiliza por GBDS como gestor de consenso.
- Kafka es una plataforma de procesamiento de transmisiones que gestiona colas de procesamiento distribuidas. Kafka gestiona colas llamadas temas, que tienen contenido en cola por productores y procesado por consumidores. Kafka distribuye eficientemente las cargas de trabajo de los temas entre los nodos disponibles.
- Ambari es una herramienta de supervisión y gestión para clústeres de Hadoop. Los administradores del sistema GBDS interactúan y administran sus clústeres a través de Ambari.
1.3. Nodos¶
Un clúster GBDS está compuesto por nodos, y cada nodo ejecuta exactamente los mismos componentes: HBase, Zookeeper, Ambari, Kakfa y el propio Subsistema de Nodo GBDS. Todos los nodos pueden recibir solicitudes de clientes de aplicaciones externas, y todos los nodos pueden enviar notificaciones asíncronas a aplicaciones de clientes externos.
El siguiente diagrama muestra la estructura general de un clúster GBDS, que es una colección de nodos GBDS:
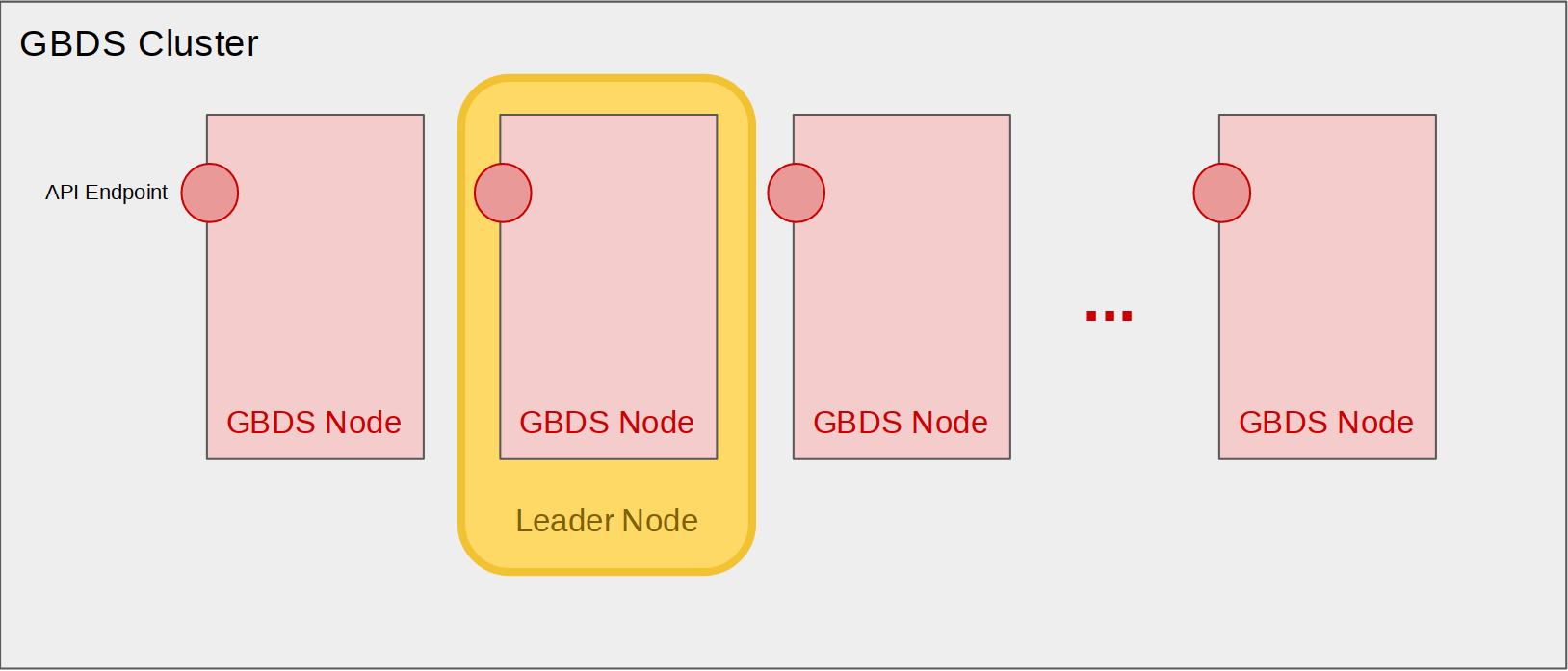
GBDS utiliza dos bases de datos diferentes: MySQL y HBase. Las plantillas biométricas se almacenan en HBase, y los datos se dividen en subconjuntos llamados regiones. Cada nodo es responsable de al menos una región. Los datos biométricos se dividen de manera transparente en regiones por HBase, en función de las capacidades de hardware de cada nodo.
La base de datos MySQL almacena información sobre metadatos de transacciones, excepciones biométricas, casos criminales, perfiles de personas inscritas y latentes no resueltos. La base de datos SQL almacena los metadatos que hacen referencia al registro de HBase, que contiene los datos de procesamiento más altos, como imágenes y plantillas.
Un nodo actúa como el Nodo Líder. Este nodo inicializará el clúster y dividirá la base de datos biométrica entre los nodos GBDS disponibles. El nodo líder es elegido automáticamente por Zookeeper.
El componente Kafka en el clúster gestiona temas (colas) para tareas pendientes (para ser procesadas por el clúster) y resultados (para ser entregados de manera asíncrona a clientes o componentes GBDS cuando se completen las tareas). GBDS tiene varios temas de tareas pendientes, uno para cada prioridad de tarea. Las tareas en temas de mayor prioridad siempre se consumen antes que las tareas en temas de menor prioridad. GBDS tiene 8 niveles de prioridad:
Menor, Bajo, Predeterminado, Alto, Mayor, Máximo y Máximo. Las aplicaciones cliente no pueden utilizar la prioridad Máxima, que está reservada para operaciones internas de GBDS. En este manual, el conjunto de temas de tareas pendientes se representa como una entidad única.
El siguiente diagrama muestra los componentes que se ejecutan en cada nodo:

El Subsistema de Nodo GBDS es responsable de la lógica ABIS. Funciona tanto como productor y consumidor de temas Kafka, como consumidor de solicitudes de clientes y productor de notificaciones de clientes.
1.4. Subsistema de Nodo GBDS¶
El Subsistema de Nodo GBDS implementa los flujos de trabajo específicos para la operación ABIS. Tiene 3 módulos internos principales: el Módulo API, el Módulo Maestro y el Módulo Notificador. Cada uno de estos módulos puede iniciarse y detenerse de forma independiente en cada nodo.
El siguiente diagrama muestra la arquitectura interna del componente GBDS y las interacciones entre los componentes.

- Cuando el Módulo API recibe una solicitud de cliente, se resuelve localmente o se envía a un tema Kafka de Tareas Pendientes con la prioridad adecuada.
- El Módulo Maestro es responsable de manejar la tolerancia a fallos, distribuir y cargar datos de la base de datos a la RAM en el momento del arranque, y procesar tareas biométricas distribuidas. Continuamente consume elementos de tareas pendientes que involucran procesamiento distribuido.
- Cuando se completa una solicitud de cliente, los resultados se consolidan por un nodo específico, que envía la salida al tema de resultados Kafka. El nodo de consolidación global donde ocurre esta consolidación global se determina mediante una función hash en el identificador único del registro que se está procesando, lo que distribuye las tareas de consolidación global de manera uniforme en todo el clúster.
- El Módulo Notificador es responsable de consumir elementos del tema de resultados Kafka y enviar notificaciones asíncronas a aplicaciones de clientes externos. El Módulo Notificador es un singleton y solo puede estar activo en un nodo específico, elegido por el administrador del sistema.
1.4.1. Módulo API¶
El Módulo API tiene un componente principal, el Manejador API, que recibe solicitudes HTTP/HTTPS de aplicaciones de clientes externos y 1) las procesa localmente; o 2) prepara la transacción para el procesamiento del clúster y la envía como una tarea a un tema Kafka de Tareas Pendientes con la prioridad adecuada, para que pueda ser procesada por todo el clúster.
El Manejador API es responsable de realizar la extracción de plantillas biométricas. Si una solicitud entrante contiene datos biométricos en bruto (es decir, imágenes en lugar de plantillas biométricas), este componente inicia procesos y/o hilos de extracción biométrica en el nodo local para generar plantillas biométricas a partir de los datos biométricos en bruto. La elección de procesos o hilos depende de la modalidad biométrica.
Las solicitudes de Inscripción e Identificación (1:N) se envían a un tema Kafka de Tareas Pendientes y son procesadas por todo el clúster.
Todos los demás tipos de solicitudes son procesados localmente por el Manejador API. Cualquier plantilla requerida por estas transacciones se extrae localmente o se obtiene de HBase, y las respuestas del cliente se envían de manera sincrónica: el Tema de Resultados Kafka y el Módulo Notificador no están involucrados.
Estas otras solicitudes pueden ser:
- Verificación (1:1): El Manejador API extrae la plantilla biométrica para la consulta (si se envía como una imagen), obtiene la plantilla de referencia de HBase, realiza la coincidencia biométrica localmente y responde directamente al cliente.
- Actualización: El Manejador API actualiza los datos biométricos y/o biométricos directamente en HBase, y envía un elemento de Tarea Pendiente a Kafka en el tema de prioridad Máxima para forzar a los nodos del clúster que tienen el registro afectado en RAM a actualizar sus registros en memoria de los datos modificados de HBase antes de comenzar a procesar otras tareas de prioridad no Máxima.
- Eliminar: El Manejador API elimina el registro de HBase y envía un elemento de Tarea Pendiente a Kafka en el tema de prioridad Máxima, forzando a los nodos que tienen el registro afectado a actualizar sus datos en memoria antes de comenzar a procesar otras tareas de prioridad no Máxima.
- Tratamiento de excepciones: El manejador API actualiza el registro de excepción en HBase.
- Tratamiento de calidad: El manejador API actualiza el registro de transacción en HBase.
- Obtener, Listar: Estas son solicitudes de solo lectura. El Manejador API obtiene los datos solicitados de HBase y responde directamente a la aplicación del cliente.
1.4.2. Módulo Maestro¶
Este módulo es responsable de iniciar (arrancar) el Nodo GBDS, gestionar el estado del clúster (por ejemplo, redistribuir la carga del clúster cuando un nodo falla) y procesar transacciones biométricas. Gestor de Nodo ~~~~~~~~~~~~~~
Este componente lee archivos de configuración, inicia otros componentes y monitorea constantemente otros nodos del clúster, y decide cómo redistribuir los datos biométricos en el clúster cuando otros nodos fallan.
1.4.2.1. Manejador de Arranque¶
Este componente es responsable de cargar las plantillas biométricas de HBase en la RAM. La coincidencia biométrica eficiente requiere que las plantillas estén presentes en la RAM. Cargar toda la base de datos biométrica en la memoria de los nodos del clúster y configurar los índices internos es una tarea que consume tiempo, pero garantiza un procesamiento rápido de las transacciones una vez que se completa el proceso de arranque.
1.4.2.2. Tubería de Procesamiento de Tareas¶
Los componentes restantes del Módulo Maestro realizan la coincidencia biométrica distribuida.
El componente Consumidor de Tareas consume continuamente elementos de los temas de Tareas Pendientes en Kafka. Siempre consume una tarea de la cola no vacía de mayor prioridad.
El componente Supervisor de Coincidencias administra los procesos y/o hilos de coincidencia (la elección depende de la modalidad biométrica) y realiza las operaciones de coincidencia biométrica entre las plantillas de consulta en la transacción y las plantillas biométricas presentes en la memoria del nodo local. La coincidencia de plantillas biométricas no es una operación trivial e implica algoritmos complejos.
El componente Supervisor de Consolidación organiza los resultados generados por los coincidentes y los envía al Consolidador Global responsable de la transacción actual, que puede no estar en el nodo local.
El componente Consolidador Global recibe resultados de coincidencia de todos los nodos que contribuyeron al procesamiento de la tarea/transacción y genera los resultados de coincidencia consolidados completos. Cada tarea/transacción se consolida globalmente en un solo nodo, determinado de manera determinista por una función hash del identificador de la transacción/persona. Esta función hash distribuye uniformemente las tareas de consolidación global entre los nodos del clúster disponibles.
Algunas transacciones, como las búsquedas latentes en sistemas forenses, requieren una operación de coincidencia adicional para refinar y/o reordenar los resultados de coincidencia, llamada Post-Coincidencia. El Supervisor de Post-Coincidencia administra los procesos/hilos de post-coincidentes para tales casos, y también se ejecuta solo en el nodo de consolidación global asignado a la transacción.
El componente Manejador de Compromiso recibe los resultados finales del Consolidador Global o del Supervisor de Post-Coincidencia y compromete los resultados de la transacción:
- Todos los cambios en el estado de la base de datos biométrica se comprometen con HBase.
- Si los resultados de la transacción requieren que algún nodo del clúster actualice sus datos biométricos en la memoria (por ejemplo, se agregó una nueva persona a la base de datos como resultado de una solicitud de inscripción), se envía un elemento al tema de Tareas Pendientes de Máxima Prioridad en Kafka.
- Envía un elemento al tema de Resultados en Kafka, que será entregado a la aplicación cliente por el Módulo de Notificación.
1.4.3. Módulo de Notificación¶
Este módulo tiene un componente principal, el Manejador de Notificaciones, que consume continuamente elementos del tema de Kafka Resultados y envía notificaciones HTTP/HTTPS a las aplicaciones cliente, informando asincrónicamente el estado de sus solicitudes.
El Módulo de Notificación es un singleton y está activo en un solo nodo del clúster en cualquier momento dado. El nodo que ejecuta el Módulo de Notificación es elegido por el administrador del sistema.
1.5. Flujos de Trabajo de Transacciones¶
Esta sección ilustra cómo se procesa cada tipo de transacción por GBDS.
1.5.1. Identificación (1:N)¶
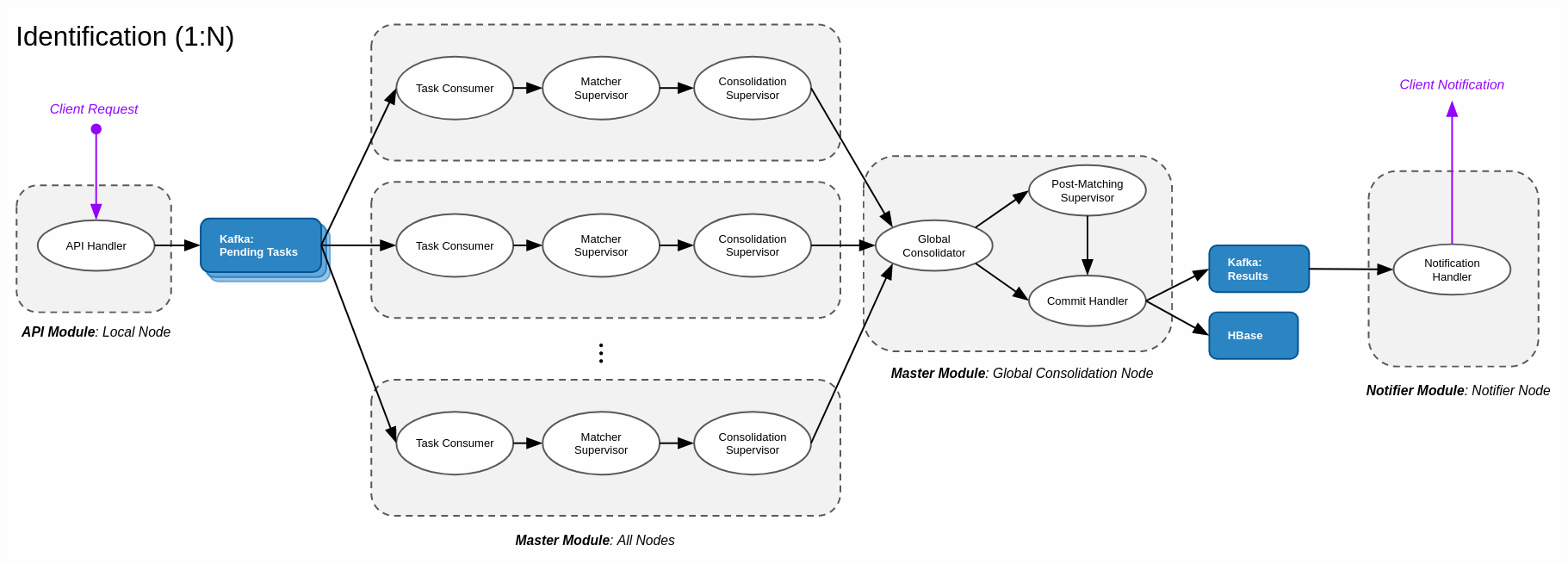
En una transacción de identificación (búsqueda 1:N), el cliente desea buscar en la base de datos biométrica coincidencias con datos biométricos de consulta. Puede ser necesario buscar en toda la base de datos. El Controlador de API recibe la solicitud en el nodo al que se envió la solicitud. Si los datos de consulta contienen datos biométricos en bruto (imágenes) en lugar de plantillas, el Controlador de API realiza la extracción de plantillas biométricas en este nodo local. Luego, la transacción se envía a un tema de Tareas Pendientes en Kafka.
Todos los nodos del clúster eventualmente consumen el elemento de un tema de Tareas Pendientes (Módulo Consumidor de Tareas) y realizan su parte de la búsqueda biométrica (Supervisor de Coincidencias y Supervisor de Consolidación). Los resultados de cada nodo se envían al Consolidador Global en el Nodo Consolidador Global, determinado por el identificador de la transacción.
En el Nodo Consolidador Global, el módulo Consolidador Global espera a que el clúster finalice la operación de búsqueda y recopila los resultados finales. Se realiza el post-emparejamiento, si es necesario (módulo Supervisor de Post-Emparejamiento), y el Manejador de Confirmación escribe los resultados en HBase y empuja un elemento al tema de Kafka Resultados.
El módulo Notificador singleton, que se ejecuta en el Nodo Notificador, consume eventualmente el elemento asociado en el tema de Kafka Resultados y envía una notificación asíncrona a la aplicación cliente, informando la conclusión de la transacción.
1.5.2. Inscripción¶
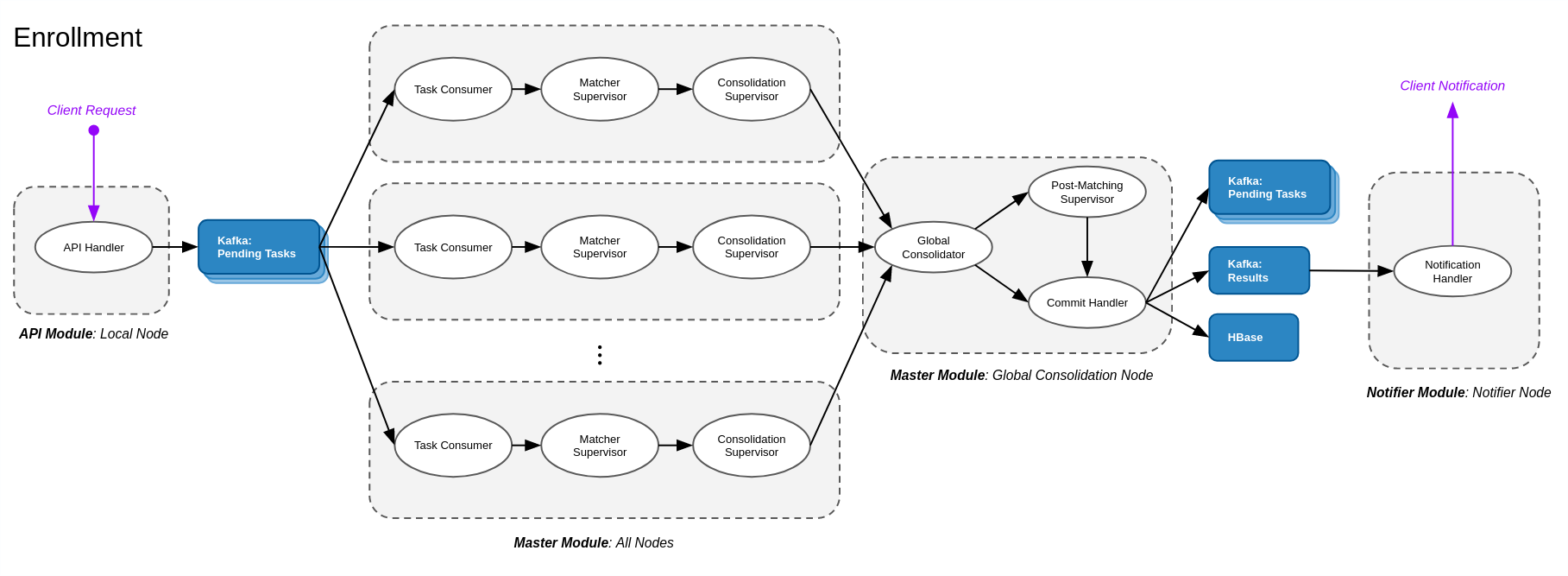
En una transacción de Inscripción, el cliente solicita la inserción de una nueva persona en la base de datos, siempre y cuando los datos biométricos no sean duplicados de un registro existente. El flujo de procesamiento para esta transacción es muy similar al de la transacción de Identificación, ya que implica una búsqueda 1:N para registros duplicados. Dado que la transacción puede requerir que todos los nodos actualicen sus plantillas locales en memoria (para reconocer a la persona recién agregada), el Manejador de Confirmación empujará un nuevo elemento a un tema de Kafka de Tareas Pendientes con Prioridad Máxima, para forzar a todos los nodos a actualizar. Si la transacción genera una excepción que requiere revisión manual, permanece suspendida hasta que la revisión sea realizada por otra transacción.
Este flujo de trabajo también se realiza cuando una transacción de actualización agrega nuevos datos biométricos a un registro existente.
1.5.3. Verificación (1:1), Obtener, Listar¶

En una transacción de Verificación, el cliente desea verificar si un dato biométrico de consulta coincide con una persona específica presente en la base de datos. Esta transacción es manejada por el Módulo de API en el mismo nodo que recibe la solicitud. El Módulo de API obtiene los datos biométricos de la persona de HBase, realiza la comparación biométrica localmente y responde al cliente de manera síncrona.
Las transacciones de Obtener y Listar recuperan registros y/o resultados existentes de GBDS. Estas son manejadas localmente por el Módulo de API, que obtiene la información solicitada de HBase y responde al cliente de manera síncrona.
1.5.4. Actualizar, Eliminar¶

En una transacción de Actualización, el cliente desea cambiar los datos biométricos o biográficos de un registro existente. Si se está insertando nuevos datos biométricos, la transacción sigue el flujo de inscripción, ya que se debe buscar en toda la base de datos duplicados. De lo contrario, el Módulo de API realiza cualquier extracción de plantilla biométrica requerida, actualiza HBase, responde de manera síncrona al cliente y empuja un nuevo elemento con Prioridad Máxima al tema de Kafka de Tareas Pendientes, forzando a todos los nodos del clúster a actualizar y reconocer los datos biométricos modificados.
En una transacción de Eliminación, el cliente solicita eliminar a una persona de la base de datos. El Módulo de API realiza la eliminación de HBase y responde de manera síncrona al cliente. También empuja un nuevo elemento con Prioridad Máxima al tema de Kafka de Tareas Pendientes, forzando a todos los nodos del clúster a actualizar y reconocer la eliminación.
1.5.5. Tratamiento de Excepciones, Tratamiento de Calidad¶
GBDS maneja Excepciones e ítems de Control de Calidad. Estos se generan cuando las transacciones de inscripción encuentran duplicados sospechosos o las transacciones de actualización no encuentran una coincidencia entre la consulta y los datos biométricos de referencia (Excepciones) y cuando se insertan datos biométricos de baja calidad (ítems de Control de Calidad). Estos ítems pueden requerir revisión manual, dependiendo de las configuraciones de GBDS. Estas transacciones actualizan el estado de los ítems pendientes de Tratamiento de Excepciones y Control de Calidad. El Manejador de API procesa estas transacciones localmente, actualiza su estado en HBase y responde de manera síncrona al cliente.